声音
物体在一定的振动频率下产生了声音。声音可以被分解为不同频率不同强度正弦波的叠加。
声音三要素
声调
音调: 由发声体振动的频率决定,频率越高(振动越快)则音调越高,听起来就越“刺耳”,反之音调越低、听起来就越低沉。
声音的音调,即音频频率或每秒的变化次数
响度
响度: 由发声体振动的幅度决定,当传播的距离相同时,振动幅度越大、则响度越大;相反,当振幅一定时,传播距离越远,响度越小。
音色
音色: 不同声音表现在波形方面与众不同的特性
声音的采集与量化
模拟信号
模拟信号:是一种连续变化的信号,可以表示为电压、电流或电荷的形式。这种信号的变化可以反应真实世界的物理量(如声音、温度、压力等)的变化。
在不同振幅、频率声波的影响下,振动膜会同步振动,并配合其他关联模块将振动转换为变化的电流。
数字信号
数字信号:是指自变量是离散的、因变量也是离散的信号,这种信号的自变量用整数表示,因变量用有限数字中的一个数字来表示。在计算机中,数字信号的大小常用有限位的二进制数表示。
将音频模拟信号转换为音频数字信号,这个过程称为音频模拟信号的数字化,整个过程主要包括采样、量化、编码等步骤
第一步,采样:以一定采样率,在时间轴上对模拟信号进行数字化。
第二步,量化:以一定精度,在幅度轴上对模拟信号进行数字化。
第三步,编码:按特定格式,记录采样/量化后的数据。
PCM
量化编码后的音频采样数据裸流,即为PCM音频数据(Pulse Code Modulation,脉冲编码调制),实际应用还会通过编码算法进行压缩封装
来自参考5
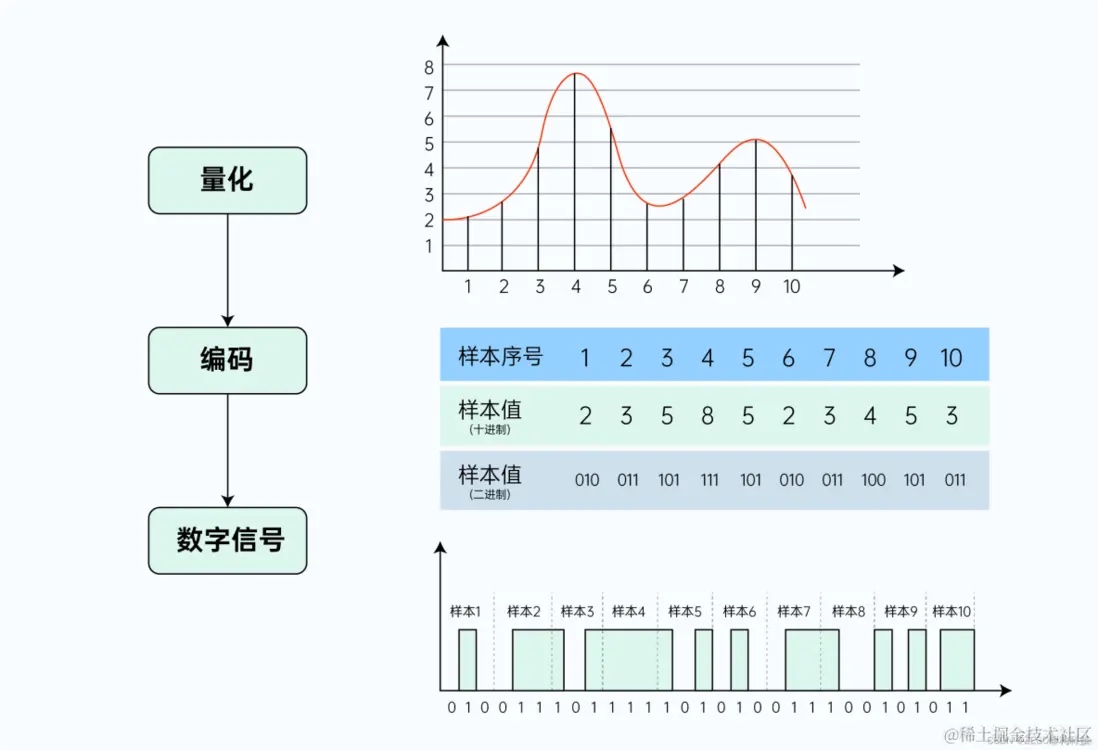
数字信号质量三要素
1.采样率
自然界的模拟信号声音转换成数字信号存储到计算机的过程中,一个是离散的,一个是连续的,就会有转换精度的描述。
采样率(sampleRate): 单位时间内(1s)对声音信号的采集次数,采样率越高,声音的还原越真实。采样率单位为Hz。
奈奎斯特采样定理:当采样频率大于信号中最高频率的2倍时,采样后的数字信号能够完整保留原始信号的信息。
因为人一般能够听到的声音范围:20Hz~20000Hz,所以很多采样率是基于这个区间而设计的。
来自参考5:
常见声音采样率:
| 采样率 | 使用场景 |
|---|---|
| 8kHz | 在语聊、通话场景,满足基本的沟通目的,同时有效减少数据量、兼容各种传输/存储环境。人说话声音频率一般在300-700Hz之间,最大区间一般为60Hz-2000Hz |
| 16kHz、32kHz | 在保证基本沟通的基础上,进一步提升音质,同时平衡带宽、存储的压力。某些音频处理算法会要求使用32KHz的采样率 |
| 44.1kHz、48kHz | 大多数的音视频应用场景。我们一般将 44.1kHz作为CD音质的采样标准 |
| 96kHz/192kHz | 更特殊的应用,比如需要对采集的音频进行后期加工、二次处理等。96KHz、192KHz等采样率对于人耳听感来说已无明显的提升,反而会增大存储、带宽的压力,对采集/播放设备也有较高要求,RTC场景一般不考虑 |
为什么是44.1kHz
找了些资料,技术 + 历史原因决定的
技术
- 奈奎斯特采样定理决定至少要满足40000Hz才能避免
- 工程选择:麦克风能接收,采集到的空气振动的频率范围远超过人耳听力。如果直接采集这样的信号,会导致出现混叠,所以必须要先使用一个低通滤波器,把高于阈值的信号过滤掉。高于40000Hz的部分实际是给低通滤波器留出空间,使得下降曲线可以落在20kHz以外,不影响音频效果
历史
- 在数字存储媒介被发明之前,早期的数字音频是要被录制在模拟录像带上的,因为只有VCR带能存储一定长度的数字音频信号。当年有两种标准NTSC/PAL
NTSC每场扫描245线,每秒钟60场,每条扫描线只需要存储三个采样就可以达到44100Hz
PAL每场扫描294线,每秒钟50场,每条扫描线也只需要存储三个采样就能达到44100Hz
人耳 20kHz 封顶,为什么数字音频都要记录和解析到更高的频率上去?
其它的说法
44.1 kHz 也允许CD格式的创作者在120毫米的唱片上记录至少80分钟的音乐(多于一个黑胶唱片的容量),在当时这被认为是一个极好的卖点。
2.采样位数
前面的采样率是音频采集量化的频率,那每次采样得到值如何描述?
采样位数: 在音频采集量化过程中,每个采样点幅度值的取值精度,一般使用bit作为单位。
来自参考5:
常用的几种采样位数
| 采样位深 | 描述 |
|---|---|
| 8bit | 早期常用的位深精度,可满足基础的通话音质需求 |
| 16bit | 被认为是达到专业音频质量的位深标准,足够完整地收录绝大多数音频场景的动态变化,适用范围广。和44.1KHz采样率一起,被作为CD音质的标准 |
| 24bit,32bit,64bit | 对于使用常见播放设备(手机、普通音箱)的用户来说,32bit与16bit的感官差异很细微,音质上的提升不明显,反而带来了更大的带宽、存储压力,更不用说64bit。并不需要盲目追求 |
3.声道数
因为音频的采集和播放时可以叠加的,因此可以同时从多个音频源采集声音,并分别输出到不同的扬声器。
声道数: 指声音在录制或播放时,在不同空间位置采集或回放的相互独立音频信号。声道数指在录音时的音源数量,或在播放时的扬声器数量。
常见的声道数
- 单声道(Mono): 只有一个声道,优点:数据量小,缺点:缺乏对声音位置定位
- 双/立体声道(Stereo): 由左声道,右声道组成,改善对声音位置定位的状态
- 四声环绕: 由左、前右、后左、后右组成,形成立体环绕。4.1声道是在四声环绕基础上,增加一个低音
- 5.1声道: 在4.1基础上,增加一个中场声道,就是电影院说的杜比音效
其它
采样数
采样数: 每帧采样的数量。
1 | typedef struct AVFrame { |
在ffmpeg中使用结构体AVFrame中的成员变量nb_samples来表示采样数
音频帧
因为音视频文件播放时,为了保证音视频同步,程序需要根据每帧的播放时间戳进行有序播放。但是每个音频采样数据太小,音频帧实际上就是把一小段时间的音频采样数据都打包。
这是根据需要人为抽象的概念。
帧时长
音频的帧时长 = 采样数 / 采样率。假设采样率为44.1k,采样数为1024。那么每帧时长约等于23ms。
采样格式
采样格式: 采样数据的保存格式
音频的采样格式分为大端存储和小端存储。按照符号划分有: 有符号与无符号。按照类型划分有:整形与浮点数。按照存储位数划分有:8位、16位、32位、64位,都是8的倍数。
1 | enum AVSampleFormat { |
封装格式与编码协议
封装: 将音频数据,元数据和其它多媒体内容组合在一起。它提供了一种标准化的方式来存储和传输音频数据,使得不同的设备和软件能够理解和处理这些数据。
封装格式由特定格式头,媒体信息,音频轨数据组成
常见的封装格式有:mp3、m4a、ogg、amr、wma、wav、flac、aac、ape等。
不同封装格式的区别
来自参考8
| 格式 | 发布者 | 年份 | 编码器 | 是否有损 | 描述 |
|---|---|---|---|---|---|
| wav | 微软 | 1991 | pcm | 无损 | 波形文件,直接存储声音波形 |
| mp3 | MPEG-1 | 1992 | mp3 | 有损 | 压缩比1:10甚至1:12,占有存储空间小,有版权 |
| aac | MPEG-2 | 1997 | aac | 有损 | 支持多声道,更高解析度,更高压缩率 |
| m4a | MPEG-4 | 1998 | aac | 有损 | MPEG-4的扩展名,由ipod采用m4a变得流行 |
| wma | 微软 | 1999 | wma | 有损 | 支持证书加密,主要应用于VOIP视频通话 |
音频码率
音频码率: 又称比特率,指的是单位时间内(一般为1s)所包含的音频数据量。
原始码率 = 采样率 * 采样位深(bit) * 声道数 * 时长(1s)
比如采样率 44.1kHZ,位深16bit的双声道的PCM数据,它的原始码率为
44.1 * 1000 * 16 * 2 * 1 = 1411200bps ≈ 1.346 Mbps
传输一分钟的音频数据需要消耗带宽 60 * 1.346 = 80.75Mbps
因为 1MB/s = 8Mbps, 所以接收原始音频的PCM数据1分钟大约要10M的流量,这个有点大,所以也可见传输过程的压缩很有必要。